Riflettendoci, “come cancellare una pagina ( URL ) da Google?” è una delle domande sulla SEO che viene posta più di frequente su forum e community, eppure raramente ho letto risposte precise e puntuali. Tutti hanno opinioni ed esperienze differenti!
I motivi per i quali si può desiderare di deindicizzare una pagina dal proprio sito o da un sito altrui sono tantissimi:
- il proprio sito è stato violato e si vogliono rimuovere dall’indice pagine contenenti spam o generati da parasite SEO ad esempio;
- è stata cambiata la struttura del sito e si vogliono togliere url rimossi o spostati;
- si fanno le pulizie SEO di primavera ( scriverò un bel post a tempo debito! ) e si vuole eliminare delle url da Google in modo da non mandare i propri visitatori su pagine non esistenti;
- si ha il desiderio o la necessità di “cancellarsi da Google” per un tantissimi motivi, ad esempio perchè si è cambiato brand name, un giornale riporta un’indagine riguardante la nostra azienda ma non l’esito positivo di un processo, circolano foto o dicerie che non vogliamo vengano diffuse;
L’ultimo problema, sicuramente più ostico, ovvero avere la necessità di eliminare notizie da Google, cioè nella pratica rimuovere del contenuto da una pagina che non sia ospitata su di un nostro sito o comunque della quale non abbiamo direttamente il controllo va affrontato con la consulenza di professionisti qualificati a livello sia tecnico che legale. Nel caso tu sia arrivato qui per questo motivo ti invito a contattarmi cliccando qui, posso metterti in contatto con persone molto preparate in materia.
Detto questo, per tutti questi motivi da tanto tempo volevo scrivere questa guida sul come rimuovere una pagina da Google definitivamente. Queste mie strategie sono il frutto delle mie molteplici esperienze sul campo: niente di ciò che dirò non è stato prima osservato dal sottoscritto in prima persona.
Partiamo dal principio ( o dalla sezione che più vi interessa usando l’indice! ).

In questa pagina:
- Cosa significa nella pratica “cancellare una pagina da Google”
- Come segnalare a Google che una pagina del tuo sito è stata rimossa
- Come segnalare a Google che una pagina è stata spostata definitivamente
- Come segnalare a Google che una pagina deve essere rimossa dall’indice
- Come e perchè assicurarsi che il crawler abbia accesso alla pagina
- Prima di continuare: controllare che le pagine rispondano effettivamente quello che pensate
- Come far scansionare al crawler la pagina da rimuovere
- F.A.Q. sulla eliminazione di URL da Google
- Non si può semplicemente usare “rimozione url” da search console ?
- Non posso utilizzare direttamente il file robots.txt?
- Come posso fare in modo che un sito non venga mai indicizzato da Google?
- Si possono utilizzare queste strategie per cancellare dall’indice delle pagine o un intero dominio di terzo livello tipo blogger o WordPress?
- E per cancellare dall’indice immagini e PDF?
- Ultime considerazioni
Cosa significa nella pratica “cancellare una pagina da Google”
Cancellare una pagina da Google significa in buona sostanza far rimuovere dall’indice del motore di ricerca una pagina specifica che risponde ad una specifica URL, acronimo di Uniform Resource Locator, ovvero dell’indirizzo al quale risiede la pagina sul web. Una volta che questa pagina è stata tolta dall’elenco, quella pagina per Google non esiste più e non verrà più servita in risposta ad una query. Semplice no? Il problema è il cattivo uso che a volte si fa degli strumenti messi a disposizione dei webmaster per questo specifico compito. Ma andiamo con ordine.
In realtà rimuovere una pagina del nostro sito dall’indice dovrebbe essere una cosa piuttosto lineare: quando il crawler di Google visita la url della pagina in questione deve ricevere la chiara indicazione che la pagina non sia più disponibile, sia stata spostata definitivamente o che non debba più essere inserita nell’indice.
Più nel dettaglio, noi dobbiamo ( nell’ordine ):
- Assicurarci che una di queste tre condizioni sia vera:
- che la pagina venga segnalata come rimossa;
- che la pagina venga segnalata spostata definitivamente;
- che la pagina venga segnalata come da non indicizzare;
- Assicurarci che il crawler abbia accesso all’indirizzo della pagina;
- Far scansionare dal crawler la pagina da rimuovere in tutti i modi possibili;
Ora vediamo come compiere tecnicamente e praticamente questi passaggi.
Come segnalare a Google che una pagina del tuo sito è stata rimossa
Per segnalare a Google che una pagina è stata rimossa dal proprio sito web bisognerà fare in modo che quando il browser cercherà di accedere alla sua URL ( all’indirizzo del documento web ), il server dovrà generare una HTTP Response 404 “not found / pagina non trovata” o 410 , letteralmente ” gone / andata ( per sempre )”.
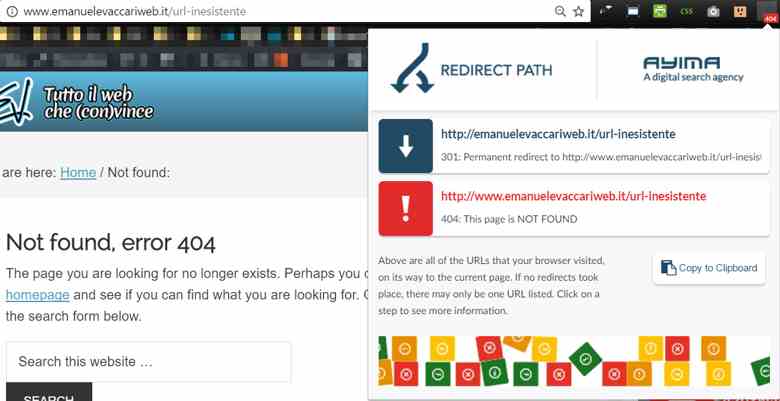
Un esempio di header response 404 sul mio sito, controllata con una estensione gratuita di Chrome
Per far rispondere ad una pagina il codice 404 potete, nella maggior parte dei casi, semplicemente cancellare dalla cartella FTP o dal CMS la pagina in questione. Per far rispondere 410 ad una pagina dovete configurare il server per farlo ( vi rimando a Google per scoprire come ).
Per vedere che codice HTTP ci viene servito da una url specifica possiamo utilizzare tantissimi tools: crawler come Screaming Frog o Visual SEO Studio oppure estensioni come l’utilissima “Redirect Path” per Chrome.
I 410 sono meglio dei 404 vero?
Ho sentito nel tempo più di una persona affermare che con i 410 si fa prima perchè la loro risposta è più “definitiva”.
Se volete la mia opinione, non fa differenza: mi è capitato di cancellare decine di migliaia di URL in un colpo solo in circa 10 giorni usando i 404 semplicemente con le strategie descritte in questo post. Ve lo dirò chiaramente: per quella che è la mia esperienza, 404 e 410 sono equivalenti al fine di deindicizzare una pagina!
Per mia esperienza la differenza è operativa: cancellare una pagina da una cartella FTP o un CMS è molto più sbrigativo che passare delle direttive al server per far rispondere 410 a delle pagine. Insomma, per quel che ho potuto osservare, cancellare dall’indice di Google una pagina facendole rispondere un 404 o 410 non fa differenza.
Aggiornamento 23/02/2016: Francesco Margherita mi ha fatto notare che una differenza è che il 410 a volte lascia il contenuto visibile al comando site: ma ne rimuove comunque la copia cache. 404 tutta la vita!
Come segnalare a Google che una pagina è stata spostata definitivamente
Per segnalare a Google che una pagina ha cambiato indirizzo ( url ), in modo che tolga dall’indice quello vecchio sostituendolo con il nuovo, dobbiamo far rispondere al server il codice di risposta HTTP 301 “spostato in modo permanente”. Anche in questo caso, vi rimando a Google per i ragguagli tecnici riguardanti la tecnologia del vostro server.
Attenti alle “catene di 301“, ovvero a concatenare reindirizzamenti: non è una pratica particolarmente gradita da GoogleBot. Controllate queste cose con i crawler e le estensioni che vi ho già consigliato in questa guida.
Inoltre sconsiglio vivamente l’utilizzo di “meta refresh“, un codice HTML che viene impropriamente utilizzato come “301 HTML”: è una soluzione molto meno pulita che può generare problemi. Andate di 301 lisci!
Come segnalare a Google che una pagina deve essere rimossa dall’indice
E’ possibile segnalare a Google , attraverso il meta tag noindex inserito direttamente nel codice HTML, il desiderio del webmaster che quella specifica pagina non venga indicizzata. In pratica la pagina dirà a Google di non voler essere inserita nell’indice. Se questa è già stata inserita, chiede al crawler di essere rimossa.
E’ molto utile per rimuovere dall’indice pagine che hanno una loro utilità o interesse per un utente del vostro sito, ma non ne hanno nessuna per utenti del motore di ricerca, come ad esempio una pagina di login ad un’area privata del sito.
E’ molto interessante sapere che questo meta tag , al contrario di quanto dice qualcuno, funziona anche al di fuori della tag <head> , ovvero funziona anche nel <body> : attenti ai commenti con HTML libero! Come si fa? Leggete questa guida.
Non mi conviene usare comunque il noindex al posto del 404 / 410 ?
Al contrario delle soluzioni proposte fino ad ora riguardanti 404 e 410, che di fatto “fisicamente” eliminano le pagine agli occhi di utenti e crawler, questa continua a tassare il robot di Google facendogli utilizzare parte del prezioso ( e dibattuto ) crawling budget, ovvero della quantità di pagine che Google ha intenzione di scansionare sul vostro sito.
Questo valore, del quale non si hanno notizie ufficiali ( da quel che ne so, solo Matt Cutts ne ha parlato anche se in modo vago ), viene determinato, con ogni probabilità, in base ad aspetti quali autorità e popolarità del sito.
In linea di massima, se una pagina non serve più agli utenti, la soluzione più pulita rimane un bel 404. Esiste anche una direttiva noindex da inserire nel file robots.txt , ma John Mueller ne sconsiglia vivamente l’utilizzo e chi sono io per dire di no al John!
Scherzi a parte, la meta tag HTML noindex funziona, non complichiamoci la vita.
Come e perchè assicurarsi che il crawler abbia accesso alla pagina
Un errore che molti commettono è quello di cancellare / reindirizzare una pagina e poi, per stare sul sicuro, mettere una direttiva di disallow per quella stessa pagina nel file robots.txt, pensando di dare il colpo di grazia.
Questo in realtà fa in modo che la pagina, per quanto possa essere stata correttamente rimossa o reindirizzata, non sia disponibile a Google per una nuova scansione, facendo si che quanto fatto ( cancellazione, rendirizzamento etc. etc. ) venga di fatto ignorato in quanto a Google risultata impossibile rilevare l’avvenuto cambiamento. Google con tutta probabilità la pagina la rimuoverà comunque, perchp non potendola visitare non la può valutare, ma ci metterà molto tempo, mesi e mesi. Lo stesso accade se mettiamo la pagina dietro password o la rendiamo orfana senza poi utilizzare gli strumenti di scansione descritti in seguito in questa guida.
Il file robots.txt in particolare deve venire utilizzato per evitare che la pagina venga scansionata e quindi indicizzata a monte, e non quando ormai è entrata nell’indice. Lo stesso dicasi per le password, che comunque preferisco come metodo di prevenzione dell’indicizzazione, come leggerai in seguito su questo articolo.
Per impararlo ad usare in modo corretto e a conoscere il robots.txt, vi consiglio l’attenta visione di questo video di Danilo Petrozzi.
Prima di continuare: controllare che le pagine rispondano effettivamente quello che pensate
Prima di far scansionare a Google le pagine è una buona idea controllare che esse siano effettivamente segnalate come rimosse / spostate. Solitamente mi faccio una lista in Excel delle pagine che andrò a cancellare, in modo da poter poi fare un controllo con un crawler e verificare che tutte le pagine rispondano effettivamente quello che vorrei.
Attenti ai soft 404
Parliamo di soft 404 quando una pagina mostra a schermo la dicitura “404 non trovata” ma in realtà restituisce un codice HTTP differente! Può capitare, sopratutto utilizzando CMS, che succeda che la pagina restituisca un codice di risposta HTTP “200” , che vuol dire essenzialmente “OK!”, e mostri invece una pagina dove afferma che il documento non è stato trovato. Potrete trovare una spiegazione più dettagliata in questa pagina . Controllate sempre i codici di risposta!
Come far scansionare al crawler la pagina da rimuovere
Come già detto, far scansionare a Google la pagina che vogliamo rimuovere dall’indice è fondamentale: solo così potrà rendersi conto di dover deindicizzare il documento. Certamente è possibile anche semplicemente rimuovere o reindirizzare correttamente una pagina e aspettare, ma i tempi si allungheranno parecchio: mi è capitato di osservare pagine non più disponibili rimanere per mesi e mesi nell’indice.
Con il metodo che vi descrivo in questo articolo, al massimo attenderete una decina di giorni! Detto questo, per far scansionare a Google la pagina da rimuovere esistono diversi modi. Il mio consiglio, nel caso vogliate sveltire la pratica di rimozione, è di utilizzarli tutti sempre e comunque. Più gli indichiamo chiaramente e con decisione il nuovo stato della pagina, più solerte sarà la risposta ( e la deindicizzazione ).
“Visualizza come Google” su Search Console
Nella Search Console esiste un comando chiamato “visualizza come Google” tramite il quale chiedere al crawler di visitare un singolo url sul nostro sito per scansionarlo.
Questo però non ci aiuta direttamente con i 404: se gli date in input un url che punta ad una risorsa inesistente, e che quindi risponde con header 404, la Search Console vi risponderà “non trovato“. Ora, sicuramente questo fa si che Google veda questo 404, ma non sono certo che venga anche segnalato all’indice l’errore: esiste un metodo più furbo (e che sono certo funzioni).
Il metodo della pagina con i link verso le 404
Se gli diamo un url che punta ad una pagina effettivamente esistente, dopo che Google avrà processato la richiesta apparirà vicino alla richiesta nella lista un pulsante con l’etichetta “invia all’indice“. Una volta premuto, ci verranno presentate due opzioni:
- Esegui la scansione solo di questo URL : viene scansionato solo l’url che abbiamo dato in input
- Esegui la scansione di questo URL e dei relativi link diretti: oltre all’url che abbiamo specificato vengono scansionate tutte le pagine che hanno un link da quell’url
“Tutto molto bello Emanuele, ma se ho una lista di pagine da rimuovere e non posso mandarle all’indice direttamente cosa mi serve questa cosa?“: ve lo spiego subito!
- Create un bella pagina orfana ( che non riceve link da nessuna altra pagina del sito ) , possibilmente escludendo gli elementi di navigazione: basterà caricare un bel file html;
- Metteteci un meta tag noindex in modo che non venga inserita nell’indice ( è una pagina “tecnica” di nessuna utilità per i vostri utenti );
- Inserite un singolo link alla URL di ogni pagina rimossa o spostata che volete venga scansionata.
- Inviate la pagina tramite con “visualizza come Google“;
- Premete “invia all’indice” dicendogli di scansionare tutti i link diretti presenti nella pagina;
In questo modo forzerete Google a scansionare, e quindi a “vedere”, tutte le URL delle risorse cancellate o spostate.
Aggiornamento 2/3/2016: come mi faceva notare Alessandro, non ho specificato quanti link per pagina.
Il buon Matt Cutts disse in tempi non sospetti che il mitico limite di 100 link per pagina non è più valido già dal 2013.
Io semplicemente ne metterei al massimo un migliaio per pagina, e controllerei nei log che il crawler abbia effettivamente visitato tutti i link. Se ne avete tanti, mettete in cascata più pagine a mo di paginazione di archivio. Controllare i log!
Ma le pagine in noindex non vengono scansionate! Che cosa stai dicendo?
Nei commenti di questo post mi è stata fatta un’osservazione ( errata ) che vedo fare molto spesso:
ma se la pagina è noindex Google non la scansiona!
Questo è errato, come lo è pensare che le pagine con meta tag noindex vengono scansionate ma non indicizzate. Come mi ha fatto notare il buon Martino Mosna le pagine vengono di fatto indicizzate, ma il noindex semplicemente blocca la pubblicazione in SERP. Un po’ come le pagine colpite da penalizzazione sono di fatto ancora dentro l’indice, ma ne viene bloccata la pubblicazione durante la generazione delle SERP dopo la query.
Quindi ricapitolando, una pagina noindex viene scansionata, indicizzata ( nel senso di memorizzata nell’indice di Google ) ma non mostrata nelle SERP. Per una spiegazione più dettagliata vi rimando a questo post di Enrico Altavilla dove sono emersi particolari molto interessanti.
Sitemap XML (Sitemap “inversa)
Un modo molto interessante per forzare il crawling delle pagine che sono state cancellate da Google è utilizzare quella che io chiamo la sitemap inversa, ovvero una bella sitemap che riporta tutte le pagine da rimuovere: inviatela a Google attraverso la Search Console in modo che il crawler arrivi, le scansioni e si “accorga” che non sono più disponibili.
Per creare sitemap da una lista di url, potete usare questo tool free online: http://www.timestampgenerator.com/tools/xml-sitemap-from-list/ Non preoccupatevi se Google vi dirà che ci sono degli errori 404 o se ci mette più tempo del solito a processare la sitemap: essendo un’azione un poco fuori dagli schemi manda in paranoia la Search Console!
Bonus: monitorare la rimozione delle pagine dall’indice
Utilizzare la sitemap inversa dei 404 vi permetterà anche di monitorare in quanto tempo verranno rimosse dall’indice dal pannello “Sitemap” > “Nome della specifica sitemap ” > “Visualizza la copertura dell’indice“: invece di aspettare come al solito di vedere il numero di pagine indicizzate “valide” raggiungere quello della pagine sottoposte attraverso la sitemap “normale”, e avere quindi desumere che le pagine che volete rimuovere dall’indice siano state, di fatto, rimosse, potete semplicemente controllare lo stato di indicizzazione della sitemap dal pannello di Search Console:
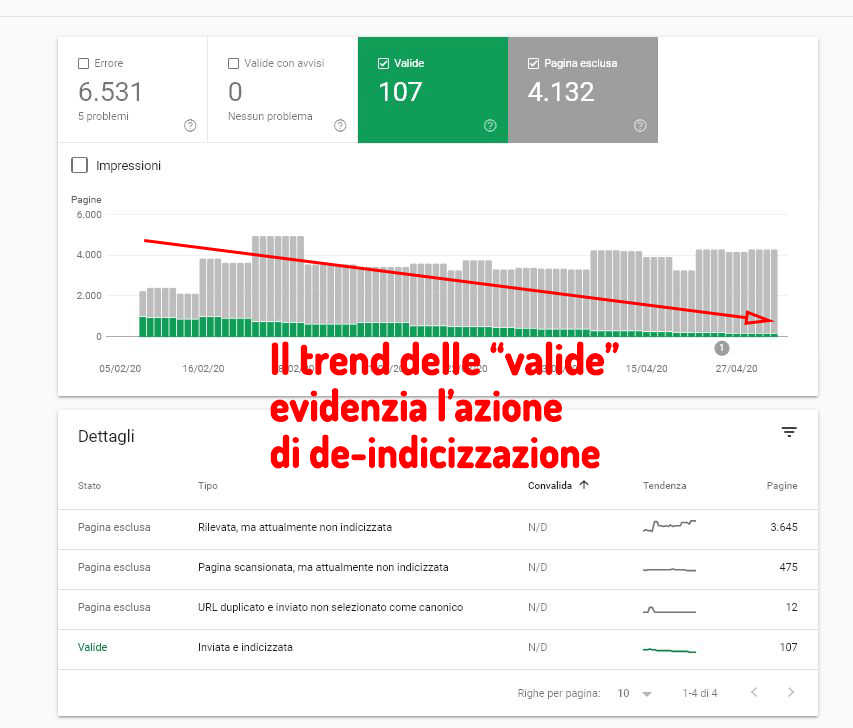
Cosa si dovrebbe osservare:
- Un calo delle pagine “valide” (ovvero di pagine indicizzate tra quelle che vogliamo rimuovere);
- Nel caso si sia optato per un 404 o un 410 l’aumento degli errori;
- Nel caso si sia optato per un noindex o un blocco da robots.txt l’aumento di pagine escluse;
Osservando questo pannello eviterete il tedio di spammare il comando site: per vedere il numero di pagine calare, e saprete esattamente quali verranno rimosse se i numeri non sono esageratamente grandi.
Se volete sapere precisamente cosa viene tolto dall’indice potete fare come me: a volte divido questa lista di 404 in più sitemap inverse per controllare esattamente, ad esempio, quali categorie di un blog che sto ristrutturando vengono rimosse prima dall’indice. Questo trucco l’ho letto nei commenti di un post del grande AJ Kohn di blindfiveyearold.com , un blog che vi consiglio VIVAMENTE di seguire!
Le sitemap inverse sono pericolose?
Prima che me lo chiediate, ho utilizzato questa strategia molte volte e non ho mai visto cali di ranking o cose del genere, Google non si arrabbia. L’unica accortezza da avere è quella di andare a rimuovere questa sitemap dalla Search Console una volta che le pagine sono state tutte de-indicizzate, ovvero quando la sitemap inversa non ha più pagine valide: questa cosa va fatta per liberare risorse di crawling a Google che non perderà tempo a “controllare” pagine che sa già che non esistono più.
Sitemap HTML
Volendo, invece che rendere orfana la pagina della quale parlavo nel passaggio dedicato a “visualizza come Google” potete inserirla nel footer ad esempio, in modo che nella normale attività di scansione del vostro sito Google arrivi a vedere molte volte le pagine da rimuovere.
Ricordate di metterla comunque in noindex e di toglierla appena le pagine verranno rimosse in modo da non sprecare inutilmente crawl budget, monitorate la situazione con la sitemap 404.
Attenzione: quando e perchè una pagina non può venire scansionata da Google
Attenzione: questi metodi sono inefficaci se una pagina non può venire “fisicamente” scansionata dal crawler di Google. Da quando ho pubblicato la prima versione di questa guida sono stato contattato da persone che dicevano che i metodi non funzionavano, per poi scoprire che veniva inibita a monte la scansione.
Per non essere scansionata da Google una pagina deve soddisfare una delle seguenti condizioni:
- essere bloccata da direttiva robots.txt ( che vengono sempre onorate da Google );
- posta dietro password;
- non avere neanche un singolo link interno o esterno senza l’attributo nofollow. In questo caso una pagina può venire comunque scansionata se inserita in una sitemap o con lo strumento visualizza come Google, ma non viene scansionata spontaneamente da Googlebot;
F.A.Q. sulla eliminazione di URL da Google
In questa sezione raccoglierò le domande più frequenti a riguardo della cancellazione di URL da Google: si tratta di domande più specifiche che avrebbero reso confusionaria la trattazione che ho fatto nei paragrafi precedenti. Se voi stessi avete qualche domanda, lasciate un commento qua sul sito e sarò felice di aiutarvi ( se ne sono in grado! ).
Non si può semplicemente usare “rimozione url” da search console ?
Non per rimuovere definitivamente una url da Google. Come, ascoltando le mie preghiere, è stato finalmente scritto chiaro e tondo nei suoi Webmaster Tools, pardon, Search Console, il tool “rimozione url” agisce in modo temporaneo.
Se ben ricordo, la rimozione dura solamente 6 mesi, perchè nella pratica di rimozione non si tratta: semplicemente nasconde temporaneamente una url dai risultati di ricerca.
Rimane un tool molto utile che rende possibile nascondere immediatamente una url, e nulla vieta di farlo e poi applicare i metodi descritti nella guida. L’unica pecca in questo caso sarà l’impossibilità di “monitorare” i risultati, e la forte possibilità di dimenticarcene: se qualcosa però va storto, potremmo accorgercene solamente dopo che la pagina torna nell’indice parecchi mesi dopo ( o non accorgecene proprio ). Io consiglio di avere pazienza qualche giorno e aspettare la naturale rimozione delle url da Google.
Non posso utilizzare direttamente il file robots.txt?
Questo è un argomento molto dibattuto. Una volta a dirla tutta l’ho pure chiesto a John Mueller che mi ha risposto così:
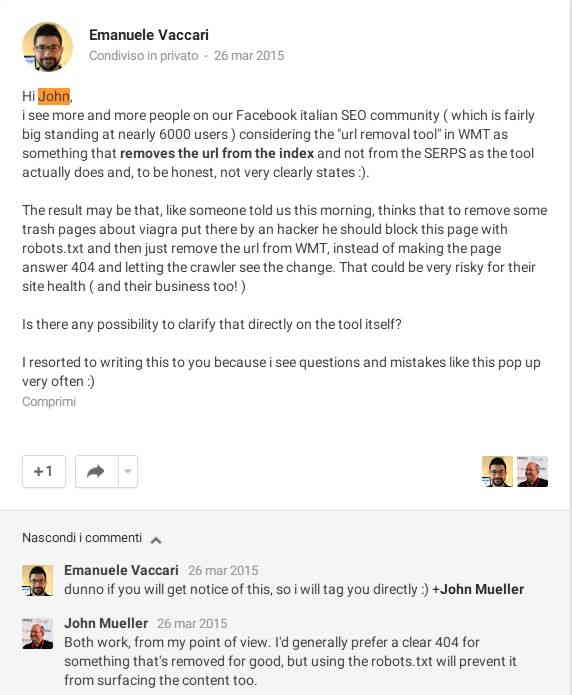
Anche lui ama i 404, ma dice anche che usando il robots.txt si fa in modo che il “content non venga a galla” nelle SERP. Certamente non potendo accedere per mesi ad una URL, e quindi non potendone controllare la qualità, logica vuole che Google rimuova le pagine dalle SERP e dall’indice, ma preferisco andare sul sicuro.
Come posso fare in modo che un sito non venga mai indicizzato da Google?
Purtroppo non si può fare completamente affidamento al file robots.txt quando si parla di deindicizzazione: più di una volta ho visto pagine magicamente indicizzate, a volte a causa di link esterni puntati direttamente ad esse ( e che per qualche motivo rendono possibile che le direttive del robots.txt vengano ignorate ), a volte per motivi che sinceramente mi sfuggono.
Come dice Maurizio Ceravolo ( che ringrazio per l’appunto ):
il robots.txt non ha nulla a che fare con l’indicizzazione, ma solo con il crawling. Quindi il robot può non andare a leggere una data pagina, però quella stesso pagina può essere indicizzata se si trovano link dalla stesso sito o da altri verso quello. In quel caso in serp spesso si vedrà che la pagina è bloccata dal bot come description e come title l’ancora dei link.
Lo scopo del robots.txt è quello di limitare la libertà del crawler, non controllare l’indicizzazione delle pagine!
Di una cosa però sono certo: il metodo più sicuro per non far indicizzare una pagina è metterla dietro ad una password. Se siete su server Apache, potete usare htpasswd : per capire come utilizzarlo e generarne uno, utilizzate questa pagina http://www.htaccesstools.com/htpasswd-generator/
Certamente il metodo con le password ha un grosso problema: non permette neanche agli utenti sprovvisti della stessa di vedere le pagine! Se volete che ne abbiano facoltà, il mio consiglio è semplicemente quello di mettere in noindex le pagine fin dalla prima pubblicazione.
Le password rimangono la migliore soluzione quando ad esempio si mette un sito in staging: mai più drammi e incubi sotto forma di interi siti di prova indicizzati erroneamente.
Si possono utilizzare queste strategie per cancellare dall’indice delle pagine o un intero dominio di terzo livello tipo blogger o WordPress?
Non ho mai provato ma penso proprio di si.
Prima di tutto, controllate che l’HTTP response sia uno di quelli dei quali abbiamo parlato, 404 o 301. Poi su di un sito self hosted, dove avete il totale controllo, usate la strategia della sitemap HTML puntando però i link alle pagine del terzo livello del quale volete rimuovere le pagine dall’indice di Google.
Se volete andarci pesante, in Search Console caricate una sitemap che punta semplicemente a questa Sitemap HTML e inserite quest’ultima anche in un elemento come il footer del sito. Ricordatevi che puntare a tante pagine che rispondono 404 non è proprio l’ideale dal punto di vista di Google, quindi lasciatela li solo lo stretto necessario se state utilizzando un sito del quale vi importa qualcosa!
E per cancellare dall’indice immagini e PDF?
Si possono usare gli stessi metodi! Come descritto in questo post, si può utilizzare una X-Robots tag per inserire nell’header HTTP il nofollow di questo genere di documenti. Per il resto, le logiche rimangono le stesse: segnalare che il documento non è più disponibile al crawler e “portarcelo davanti”.
Ultime considerazioni
Vi incollo qui delle considerazioni di Mosna che mi sono piaciute moltissimo e sulle quali vi invito a riflettere:
Comunque va anche detto che Google non dimentica mai nulla. Se una pagina 404 torna in 200 (o in 301 su un altro URL) e Googlebot la scansiona, sei generalmente di nuovo in SERP come se nulla fosse successo.
Sta cosa è al tempo stesso comoda e decisamente fastidiosa: non esiste nei fatti un modo per rimuovere davvero i dati sui nostri siti dagli archivi di Google. Possiamo solo controllare quello che compare in SERP…
Vi consiglio inoltre la visione di questo video per approfondire la questione dei 404:
PS: chi coglie la citazione nell’immagine in evidenza ha tutta la mia stima!
P.S. Hai visto che non scherzo quando dico che nei miei contenuti non c'è posto per la fuffa?
Tutto scritto da me, nessuno stagista e niente ghost writers. Se ne avrai voglia ci sentiamo al prossimo contenuto, io ti aspetto!

Ciao e complimenti per l’articolo. vorrei fare una domanda, se nel sitemap.xml si inseriscono piu links a quella che potrebbe essere interpretata come la pagina dello stesso prodotto (praticamente ogni variante di un prodotto produce una pagina (es: Proddotto-marca-xl-rosso, prodotto-marca-xl-giallo, ecc. e idem per il nome del prodotto) cosa succede? il sito puo essere penalizzato? come si comporta google? Grazie
Ciao Mastro,
il sito non viene mai penalizzato per contenuti duplicati, ma questi generano una serie di problemi che è comunque preferibile evitare.
Quello che ti consiglio è di implementare una soluzione che ti permetta di gestire le varianti nella stessa pagina se gli oggetti differiscono solo per una specifica qualità ( ad esempio, la variante colore ), oppure di implementare il “rel=canonical”.
Puoi trovare la guida di Google qui: https://support.google.com/webmasters/answer/66359?hl=it
Spero ti possa essere utile!
Ciao Emanuele,
complimenti per l’articolo, un sacco di info utili, ma non ho trovato quello che mi serve: come posso eliminare (o comunque non mostrare nella SERP) lo stesso file robots.txt del mio sito? E’ molto sgradevole che compaia per query legate al nome di dominio.
Grazie in anticipo e buona giornata!
Ciao Roberto,
mi fa piacere se l’articolo ti è stato utile! Se stai usando Apache puoi usare questo codice nel file .htaccess
Header set X-Robots-Tag “noindex”
Dovrebbe funzionare! Dico dovrebbe perchè non ho mai sentito l’esigenza di togliere il robots.txt dai risultati di ricerca, posso chiederti la ragione precisa? se cerchi il brand compare tra i primi risultati?
Ciao Emanuele,
grazie mille! Provo subito…
si cercando per il nome di dominio compare tra i primi risultati, insieme a tanti siti di analisi e comparazione tipo alexa, etc.
Per quelli non ci posso fare niente, però almeno il file robots vorrei non renderlo visibile, magari ad un utenza inesperta potrebbe sembrare un file infetto o robe simili.
La posizione in cui inserire la stringa all’interno delll’.htaccess che mi suggerisci è indifferente?
Di nuovo grazie,
Roberto
Direi tu possa metterlo in fondo al file senza alcun problema
Ciao ,
devo rimuovere delle pagine 404 dall’indicizzazione di Google; per farlo sto seguendo le indicazioni da te riportate.
Sono arrivato alla creazione della pagina orfana da dare in pasto a Google, ma mi sfugge un dettaglio; per inserire i link da rimuovere nella pagina HTML devo usare il codice rel="nofollow" su ogni link o inserirlo solamente nelle metatag iniziali?
Ciao Simone!
Se metti rel="nofollow" sui link la pagina non servirà a nulla, perchè Google non vedrà le pagine in 404.
E' invece un'ottima idea mettere la pagina in noindex nelle metatag in modo che la pagina con solo i link non venga indicizzata ( non ne hai bisogno e crea solo confusione ).
Ciao Emanuele, conosci un metodo veloce per inserire centinaia di link in un file html? Sto utilizzando atom e con degli "shortcode" di questo tipo ul>li*477 mi genera automaticamente una lista di 477 tag li aperti e chiusi ovviamente vuoti. A questo punto il problema è inserire i link all'interno di questi tag li evitando di doverli inserire ad uno ad uno. Se conoscessi un comando per farlo sarebbe magnifico. Sarebbe ottimo anche una cosa del genere in un altro editor. Grazie comunque.
Ciao Vito, non so esattamente cosa c'entri con il cancellare le pagine ma provo a risponderti :).
Se hai una lista URL puoi usare semplicemente un concatenate su excel aggiungendo i tag! Fai una colonna URL e poi metti la stringa con il tag a fino alla dichiarazione dell href e poi chiudi la dichiarazione, metti un archor e chiudi il tag. Spero di essermi spiegato 🙂
Ciao Emanuele,
Abbiamo inserito la mappa all'interno della search console, ora ci è comparso l'avviso con descrizione:
"Quando abbiamo testato un campione degli URL della tua Sitemap, abbiamo riscontrato che Googlebot non era in grado di accedere ad alcuni di essi a causa di un errore di stato HTTP. Tutti gli URL accessibili verranno comunque inviati."
Ed esempio:
"Errore HTTP: 404" URL: '/link-di-esempio/
Sai dirci cosa significa? È normale?
Non ci è chiara anche la parte dove dici:
"Utilizzare la sitemap dei 404 vi permetterà anche di monitorare in quanto tempo verranno rimosse dall’indice: invece di aspettare come al solito di vedere il numero di pagine indicizzate raggiungere quello della pagine sottoposte attraverso la sitemap, dovrete fare il contrario controllando che nel tempo scendano!"
Potresti cortesemente spiegarcela più dettagliatamente?
Grazie,
Simone e Sara.
Si è assolutamente normale.
Da quella sitemap potete vedere in quanto tempo vengono rimossi dall'indice le URL: quando il grafo delle URL incluse raggiunge lo zero sono state tutte de indicizzate.
Ciao Emanuele,
ottimo articolo, complimenti. Oggi però ho notato una cosa quando si fa "Visualizza come Google" e non so se c'è sempre stata:
Note: The page will be considered for indexing only if it meets our quality guidelines and avoids the use of no index directives
Questo si scontra con il fatto che le pagine in noindex vengono di fatto indicizzate ma non mostrate nei risultati, che è vero in condizioni "normali" ma stando all'avviso non lo è in questo caso specifico quando andiamo a forzare il passaggio del crawler. Quindi mettere in noindex la pagina orfana potrebbe non produrre alcun risultato.
Sono io che me ne sono accorto solo ora o questo avviso c'è sempre stato e non è veritiero?
Grazie
Andre
Ciao Andrea, grazie per il contributo! Il fatto è che viene usato "indexing" nell'accezione comune del termine, dove "index"="risultati delle SERP". Anche io ho sempre usato i termini in modo ambiguo fino al venir "svegliato" da Mosna. Detto questo, quello che vogliamo fare è che il crawler legga la pagina e la veda noindex, cosa che accade usando "visualizza come Google" 🙂
Ciao Emanuele,
facendo un command site del mio sito ho visto che mi appaiono diverse pagine indicizzate vuote, cliccandoci entro nel sito e mi appare "Sorry, the page you are looking for has not been found". Ho visto che ce ne sono diverse e pensavo di adottare il tuo sistema per rimuoverle, il problema è che di html ne capisco poco e vorrei evitare di fare disastri, mi potresti segnalare un esempio di pagina con il codice, ….. noindex e link.
Grazie
Mario Nicoletta
Ciao Mario, se queste pagine rispondono con un header 404 non devi fare nulla, solo aspettare. Prova ad utilizzare un'estensione Chrome come Redirect Path che ti da il codice: http://ayi.ma/jiy4o
Guida davvero molto interessante e che tratta l'argomento cancellazione/rimozione dall'indice in maniera esaustiva. C'è una sola cosa che non mi è chiara: nel caso in cui si usi un CMS e la pagina scansionata dal BOT venga non trovata con "visualizza come Google" , non esiste un metodo certo ed inequivocabile per capire se venga effettivamente segnalata come errore 404 e più in generale per capire quale codice di errore venga generato in risposta?
Ciao Marco, grazie per le parole gentili!
Per sapere che risposta viene generata basta scansionare la URL con un crawler o direttamente con Chrome con estensioni quali "Redirect Path", vedrai lo stesso HTTP header response http che il crawler di Google
Ciao Emanuele, molto utile!
Mi farebbe piacere avere il tuo parere su una scelta da compiere, infatti anche io ho avuto un problema di sito bucato (nel mio caso si è trattato di iniezione di contenuti), il sito è stato prontamente ripulito ma purtroppo (a distanza di circa 10 gg) le scorie rimaste consistono in centinaia di pagine di spam che ormai verranno viste dallo spider come pagine 404 ma che risultano ancora indicizzate con il contenuto spam iniettato. Sono indeciso sul da fare anche perchè ho raccolto pareri contrastanti. In teoria sarebbe possibile:
1) Aspettare il ripassaggio naturale del BOT
(Il rischio forse è che trattandosi di junk pagine il BOT potrebbe anche decidere di non passare presto)
2) Chiedere una cancellazione temporanea delle pagine tramite la google search console
(No comment)
3) Chiedere la rimozione definitiva degli url in questione tramite l'apposito tool in GSC
(sembrerebbe la soluzione forse più logica e in qualche modo anche indicata come solutione facoltativa dalle direttive google però dare in pasto centinaia di ex pagine farlocche diventate 404 non, mi perplime)
Ovviamente la soluzione mi interessa in chiave di non compromissione del ranking e/o recupero di quello eventualmente perso (un certo danno c'è stato)
Un'altra cosa ….. da un controllo dei backlink risultano dei siti (non molti) che spammavano verso le suddette pagine e anche verso pagine già esistenti che però sono adesso perfettamente indicizzate e pulite. Che fare? Rinnegare i link o lasciar perdere?
Grazie per il tuo punto di vista.
Ciao Marco,
quello che farei è la scelta numero 4: forzare il passaggio del bot per fargli vedere le 404 come ho scritto nella guida.
Non esiste nessun tool che rimuove definitivamente le URL in Search Console, o se c'è mi è sfuggito :). Esiste il tool di rimozione temporanea che però non rimuove ma semplicemente "nasconde".
Io farei un bel disavow sia sui link verso le pagine spazzatura sia dai siti che mandano link spazzatura alle pagine "vere", per far capire a Google che sei una vittima e stai pulendo tutto. In bocca al lupo!
Ciao Emanuele,
complimenti per i tuoi articoli sempre ben scritti e chiarissimi.
Sto tentando di dare una ripulita al mio vecchio sito basato su WordPress. Sono arrivato al punto dolente (per me) dei tag che in passato ho sempre utilizzato malissimo. Mi ritrovo con centinaia di tag sul sito (ed indicizzati su Google) che magari fanno riferimento ognuno ad un singolo post: non è una situazione ideale :/ L'idea è quella di deindicizzarli tramite sitemap dopo averli segnati come noindex , aspettare che spariscano da Google per poi fare un ripulisti cancellandoli e riorganizzando le poche decine che reputo fondamentali, infine riattivare la loro indicizzazione.
Questo articolo mi ha risolto molti dubbi, tranne uno: ne vale veramente la pena?
Si ne vale assolutamente la pena, alleggeriresti la struttura e miglioreresti la qualità media delle pagine sul sito, cosa MOLTO importante. Se devi tenere solo alcune tag invece di mettere in noindex cancella le tag sbagliate e tieni online quelle giuste, fatti solo una sitemap 404 come scritto nella guida per accellerare i tempi di deindex
Grazie per il suggerimento Emanuele, procederò come da tue indicazioni. E scusami per il doppio commento, ma pensavo che il primo non fosse stato inviato.
Ma figurati Roberto, nessun problema :). In bocca al lupo, fammi poi sapere come va!
Ciao Emanuele,
approfitto ancora di questo spazio per un'ulteriore delucidazione, se possibile.
La settimana passata ho eseguito quanto da te raccomandato. Quindi ho cancellato i tag inutilizzati dal mio sito (circa 620) ed ho creato la sitemap con i link non più presenti. Poi l'ho data in pasto a Google.
Dopo qualche ora, in Search Console, nella riga relativa alla Sitemap, sono comparse le prime statistiche:
elementi inviati 620, indicizzati 430, avviso presenza di errori 404 (ovviamente).
Poi si è fermato qui. Da oltre 6 giorni non si è più mosso un dato, se non in "Errori di scansione" che sono passati molto lentamente da 0 a 35. Il crawler sta facendo il suo lavoro perché vedo, in Statistiche di scansione, una media di 170 pagine scansionate al giorno. Inoltre c'è un altro fatto che mi lascia perplesso ed è il risultato del comando "site:miosito.com" che mostra un andamento altalenante (qualche elemento in meno un giorno e qualche elemento in più il giorno dopo) delle risorse indicizzate, nonostante il sito, a causa della riorganizzazione, non abbia avuto nuovi contenuti da quasi 3 settimane.
E' normale questa lentezza/andamento nella deindicizzazione delle pagine?
E poi la domandona finale: come diavolo faccio a reimpostare in inglese Search Console? 😀
Ciao Roberto, in ordine sparso:
– Da quel che ho visto adesso a volte non si riesce a monitorare la sitemap al contrario, per vedere in quanto vengono deindicizzate le cose. Serve comunque a forzare Google nel vedere le 404 ( e velocizzarne la digestione );
– 170 pagine al giorno non sono tantissime se avevi 620 tag inutili ( e quindi almeno altrettanti articoli ), sicuro di non avere il server molto lento o di avere pochissimi link? Mi sa di crawl budget bassino;
– Il comando site pesca i risultati da data center diversi che possono avere dati diversi. Inoltre non mostra tutte le pagine indicizzate, ma solo una parte. E' tutto normale insomma, sopratutto con centinaia o migliaia di pagine si vedono un sacco di oscillazioni;
Fammi sapere poi com'è andata!
Caro Emanuele,
complimenti per il tuo articolo che, ancora una volta, conferma quanto dico circa l'ottimizzazione dei siti: molte volte basta ritrovare il criterio logico che muove il tutto.
Circa un mese fa mi è stato bucato un sito che, in appena un anno, aveva ottenuto risultati quasi incredibili su TUTTI i suoi articoli, senza alcuna link building ed in un settore concorrenziale. Veramente andavamo fortissimo (con appena 20 articoli peraltro).
Poi tale sito è stato bucato con l'iniezione di centinaia (forse migliaia?) di pagine con permalink analogo a questo: u92728-iqzki-bqixi-atbqic-p920170407-okmyeks.shtml
Notifica di sito potenzialmente compromesso.
Subito il sistemista ha ripulito il tutto (non appena ho letto la notifica in Search Console) ed abbiamo ottenuto la riconsiderazione in poche ore.
Da allora, i vecchi contenuti vanno forte, mentre i nuovi si indicizzano, ma non si posizionano bene. Dando il "comando site" ci sono, ma è come se fossero stati penalizzati organicamente.
Allora ho preferito seguire il tuo consiglio per eliminare dall'indice le restanti scorie lasciate dagli hacker (avevo 27 contenuti indicizzati più 80 errori 404).
Su 80 link 60 circa sono stati eliminati dall'indice ma, evidentemente, ne ho saltati una ventina che, pur ripetendo nuovamente il lavoro, non vengono cancellati in alcun modo da Google.
Ho ripetuto l'operazione in giorni diversi e con pagine non indicizzate diverse. Nulla.
Hai consigli in merito?
In attesa di una tua risposta, ti ringrazio anticipatamente e rinnovo i complimenti,
Giovan Giuseppe
Ciao Giuseppe, innanzitutto grazie per le parole gentili.
Mi spiace per quello che ti è capitato. Una volta segnalate le pagine a Google e verificato che i link in questione rispondano 404 puoi solo aspettare. Attento a non scambiare i falsi positivi della Search Console per errori veri e propri, preoccupati solo che scansionando con un crawler non ci siano vicoli ciechi.
Riguardo al posizionamento, potrei fare 1000 ipotesi ma sarebbero campate in aria senza conoscere il sito.
I complimenti non sono per piaggeria naturalmente, ma perché sei riuscito laddove io mi ero solo avvicinato.
Per quanto riguarda invece la tua risposta, immagino che, scrivendo "scansionando con un crawler non ci siano vicoli ciechi", faccia riferimento al file robots.
I contenuti si sono indicizzati e vengono fuori dando il comando site:, ma non si posizionano né vengono dalla ricerca più efficace: "titolo + nome di dominio".
Il sito è MiglioriPc.it
Se ti va di darmi una tua opinione, sarò lieto di leggerla. Non capisco l'antitesi tra vecchi contenuti e nuovi: i primi migliorano, i secondi non vengono considerati.
Spero che sia solo fatto di tempo in quanto avevo l'impressione che, prima dell'attacco, il mio progetto, nella sua semplicità strutturale, fosse molto apprezzato sia dagli utenti che da Google.
Buon lavoro caro Emanuele ed a presto,
Gio
I vicoli ciechi possono essere causati da robots, da "nofollow" di link o pagine intere, da link rotti in struttura/interni e tutto quello che rende la scansione più difficile del dovuto per Google. Il crawler deve entrare e trovare una struttura chiara, il più lineare possibile, con meno link interni possibili e distribuiti in modo da avere più link sulle pagine più importanti. Buonsenso e praticità insomma!
Se le pagine non vengono fuori neanche cercando esattamente il titolo con le due virgolette ( " ) è strano, ma sarebbe da indagare. Intanto controlla la struttura.
Purtroppo non ho fisicamente tempo per dare un'occhiata al tuo sito ora come ora. In bocca al lupo 🙂
Salve sto cercando di eliminare delle pagine dall'indice di google, poichè le ho cancelatte dal sito, sostituendole con altre. Volevo inizialmente fare dei redirect tramite htaccess, ma sfortunatamente ho un server Windows. Ho attuato queste procedure ieri:
Il metodo della pagina con i link verso le 404
Sitemap XML
Sitemap HTML
le ho fatte tutte 3 per andare sul sicuro, ora la sitempa è stata scansionata riscontrando naturalmente questo errore:
URL non accessibili
Quando abbiamo testato un campione degli URL della tua Sitemap, abbiamo riscontrato che Googlebot non era in grado di accedere ad alcuni di essi a causa di un errore di stato HTTP. Tutti gli URL accessibili verranno comunque inviati.
Sto attuando una buona procedura per eliminare le pagine già cancellate dal mio host anche dagli indici di google e orientativamente quanto tempo ci vuole, naturalmente le pagine riportano l'errore HTTP Error 404.0 – Not Found
comunque ottimo blog, l'unico chiaro su questo argomento, credo sia anche utile aggiungere le differenze tra i server linux e windows (sopratutto su aruba che non permette alcuna gestione di redirect) per questo argomento!! grazie mille comunque.
Ciao Tommaso, scusa il "ritardo" nella risposta ma è un periodaccio.
Detto questo, partiamo col dire che il redirect si può fare anche su server Windows e dovresti parlarne con il tuo hosting. Ricordo che c'è un modo anche solo da FTP, ma evitando server Windows come la peste non saprei aiutarti.
L'errore in search console come giustamente dici tu è normalissimo! E' un uso "improprio" quello che consiglio, ma è efficace.
Solitamente in un paio di settimane, se le url sono nell'ordine di qualche centinaio, dovrebbero bastare, ma dipende molto anche dal crawl rate e tante altre cose che difficilmente puoi prevedere o controllare.
Ti ringrazio per i complimenti e, già che ci sono, ti auguro una buona Pasqua
PS: si i commenti sono sottoposti a revisione, in modo da poterli pubblicare con risposta 🙂
Ciao Emanuele,
Sto seguendo tutti i tuoi preziosi consigli. Ho avvisato Google tramite search console delle mie pagine 404 e ho creato la pagina orfana likando nella sorgente tutti gli url rimossi.Sto però avendo delle difficoltà nella creazione della sitemap con il tool che mi hai consigliato e anche con altri (tipo screaming frog), sostanzialmente mi generano tutte sitemap vuote il che mi fa pensare che io abbia sbagliato qualcosa.
Puoi darmi qualche consiglio?
Jenna
Ciao Jenna, dovrei vedere il sito per capire, l'unico motivo che mi viene in mente così su due piedi è che tu abbia bloccato la scansione al crawler di Screaming Frog. Il tool online che ho consigliato nella guida ha bisogno della lista di URL con la quale formare la sitemap, sei sicura di non stargli dando in pasto solamente la root del dominio ?
Ciao, ottimo articolo!
Domanda..
Devo lasciare in piedi per un mio sito solo la home in italiano ed inglese.
Ho messo tutte le altre pagine ed articoli in "bozza" direttamente dal cms.
Ho reindirizzato il tutto con 301 alle due home.
Ho inoltrato a google nuova sitemap con le due sole url della home.
Sono passato in search console ed ho provveduto alla rimozione di tutte le url.
È sufficiente.? O devo fare ancora qualcosa?
Ciao Tommaso, grazie per le gentili parole. Direi che dovrebbe essere sufficiente, puoi sveltire il processo con la sitemap dei 301.
Ciao Emanuele,
ho letto più volte l'articolo, messo in pratica ma non risolvo il mio problema. Mi spiego.
Ho un dominio registrato tanti anni fa. Inizialmente per gioco poi quello per il mio lavoro. Scrivevo articoli tecnici. Prima creavo pagine con estensione .asp. Poi .html. Ho conosciuto joomla ed ho cominciato a pubblicare con e senza suffisso ecc..
Ad oggi, mi trovo nella WMTool URL del tipo "/pagina.asp" che non esistono da tantissimi anni.
Stato 404. E' una cosa noisa ma non ne vengo a capo.
Ho anche provato con "Redirect 410 /pagina.asp" ma sempre nella WMTool di Google mi appare la dicitura stato 410. Ripetutamente.
Spero di essere stato chiaro ed attendo un tuo consiglio.
Grazie
Giuseppe
Ciao Giuseppe, purtroppo il crawler di Google è famoso per visitare URL cancellate anche ANNI prima, è una cosa che ho riscontrato io stesso.
Il 410 non è un "Redirect" ma è un "Gone", cosa che dovrebbe in teoria funzionare come "non tornare più" ma che per quel che ho visto io è uguale a un 404. Se hai messo in pratica tutti i punti della guida dovrebbe risolversi… quando ne ha voglia lui. Detto questo i falsi positivi in Search Console sono l'ordine del giorno ma non penso siano particolarmente dannosi per il tuo sito. In bocca al lupo!
Ciao @Emanuele,
complimenti, davvero, per questa guida quanto mai esaustiva! Hai toccato tutti i metodi possibili e immaginabili (forse no, però ci hai provato 😀 ) su come cancellare una pagina da Google.
Senti, io ho questa problematica: sto analizzando un sito (wordpress) di un cliente che ha una serie di pagine (una decina al momento) che risultano visibili in serp (e anche abbastanza ben posizionate) con URL come questi:
– http://www.sitocliente.it/rtuiehj9
– http://www.sitocliente.it/afB68dgfh
etc …
Se clicco su questi URL arrivo a pagine dove vedo, al massimo, un 'immagine .. nella peggiore dei casi la pagina (con tanto di header, footer, etc ..) è bianca. Non ho errori 404!
Hanno bucato il sito? Come dovrei, secondo te, comportarmi?
Inoltre ti chiedo se tutti i file sitemap.xml che crei (anche quelli dei 404) li inserisci nel robots.txt.
Grazie e ancora complimenti 🙂
Ciao Guglielmo,
intanto grazie per i complimenti.
Riguardo al tuo cliente dovresti controllare sia che non ci siano errori PHP ( ci sono diversi problematiche che danno la malefica "white page" su WordPress ad esempio, e sta cosa dell'immagine mi puzza… ) sia che non siano effettivamente bucate. Io mi rivolgerei ad un sistemista per non morirci dietro.
Le sitemap 404 non le metto nel robots perchè non le aggiorno mai e non voglio che Google le scansioni ogni volta perdendo tempo a scansionare le 404. Probabilmente può sveltire un po' il processo ma su siti grandi crea un "collo di bottiglia" per il crawler. Se devo aggiungere delle URL aggiungo ulteriori Sitemap 404.
Spero di averti risposto, in bocca al lupo!
Ciao Emanuele, grazie per la tua cortese risposta.
Per errori PHP intendi a livello di codice, niente di "sospetto", giusto?
Ok, proverò a sentire il webmaster e/ o l' azienda che dà l' hosting, magari c' è anche qualche problema di virus … speriamo di no!
Ok, quindi con i vari sitemap utilizzi la search console la prima volta e basta ..
Grazie!
Possono esserci anche errori, tipo whitespace ( spazi ) o newline ( mandate a capo ) messe nel punto sbagliato possono generare cose di questo tipo tipo whitepages. La cosa strana è la url in questo caso, <em>cosa la genera?</em> Chiama un sistemista bravo fidati!
D'accordo, grazie ancora! 😉
Ciao Emanuele e complimenti per l'articolo.
Volevo sapere se potevi spiegarmi come creare una pagina html ed inserire all'interno i link che restituiscono error 404, per i quali richiedere la rimozione a google. Grazie mille
Ciao Antonio intanto grazie per il commento e scusa il ritardo nella risposta.
Per creare una pagina HTML basta un qualsiasi editor di testo nel quale inserire la sintassi corretta. Trovi una guida basilare qui : http://www.html.it/pag/16033/struttura-della-pagina/
Spero di esserti stato d'aiuto, in bocca al lupo!
Ciao Emanuele, il tuo articolo è ampiamente chiaro e chiarisce molto bene parecchi dubbi. Complimenti veramente.
Ho appena visto il link che hai suggerito ad Antonio per la creazione della pagina HTML. Ti chiedevo però se cortesemente potevi postare uno screenshot o un link ad un'immagine con uno schema/bozza della pagina HTML da creare ed inserire i vari elementi (tag e link).
Ciò sarebbe veramente di grande per me ed altri che iniziamo ad avvicinarci a questo immenso mondo SEO.
Ti ringrazio infinitamente se potrai.
p.s. se riuscissi poi ad intregrarlo nell'articolo sarebbe il massimo 🙂
Ciao Daniele,
grazie per il consiglio, durante la prossima revisione dell'articolo inserirò un template del foglio HTML. Detto questo scoprire come farlo da solo ti farà imparare moltissimo :). Io non ho fatto corsi ne avuto veri e propri maestri, mi sono sporcato le mani per 16 ore al giorno per anni ed è stato tempo ben speso!
ciao Emanuele,
scrivo questo commento nell'ottica di aiutare e condividere conoscenza, soprattutto per evitare ad altri l'errore che ho fatto io.
In sostanza: il mio sito, molto ben indicizzato, ha cominciato una lenta e inesorabile discesa a giugno scorso. Dopo accurata analisi ho scoperto che il problema sta nelle pagine del forum (bbpress): ogni thread genera n pagine "nascoste" dedicate a ogni singola risposta di ogni singolo utente.
In breve: mi sono ritrovato 20k pagine indicizzate di troppo.
Quindi: ho messo "noindex" in metatag, lasciato le pagine on line, e le ho date in pasto a google tramite search console.
E' successo un casino vero: sito praticamente ucciso, da 1 milione di utenti al mese proietto adesso forse 50mila utenti mese..
Ed ecco l'errore: la tua procedura va fatta SOLO DOPO AVER RIMOSSO LE PAGINE (reindirizzate in 301 o 404). Il "noindex" non basta e sostanzialmente google se ne frega.
Quindi ora ho reindirizzato tutto (sono riuscito a creare un rewrite sensata che reindirizza alla home del sito tutte le reply senza far danno al funzionamento del forum) … devo però aspettare che Google capisca.
MORALE: attenzione alla procedura, datela in pasto a google attraverso search console SOLO DOPO AVER RIMOSSO LE PAGINE (i metatag noindex e nofollow non bastano) ciao e complimenti cmq per il sito… per chi è impallinato come me è una manna.. baci e abbracci
Ciao Alessandro,
mi spiace molto per quello che ti è successo ma il problema è intrinseco nella meccanica del forum non nella procedura per forzare la scansione che ho scritto qua :).
Innanzitutto le pagine relative ai commenti/risposte vengono generate anche da WordPress e Google solitamente le ignora escludendole automaticamente dall'indice. Sono sicuro lo faccia anche con BBPress che è un software per forum molto usato. Detto questo uno potrebbe pensare che il problema sia il crawling verso queste pagine. Hai controllato nel log che fosse effettivamente così?
Detto questo, quello che penso sia successo è che il noindex venga applicato anche a monte alle pagine del thread stesso: praticamente hai deindicizzato tutto il sito. Quello che avresti dovuto fare ( e devi fare anche ora, togli quei redirect alla home per carità! ) era semplicemente mettere un canonical verso il thread ad ogni sua risposta e, una volta digerito da Google, bloccare da robots la scansione delle risposte per risparmiare crawl budget se vuoi essere 100% in ottica di ottimizzazione. Mettere noindex non è la procedura corretta così come non lo sono i redirect.
La procedura va benissimo anche per i noindex quando sono applicati sensatamente, va bene in qualsiasi istanza si voglia forzare il crawl di determinate risorse.
Concludo dicendo che certi interventi andrebbero sempre effettuati seguiti da un esperto per non incappare in disastri, in questo caso bastava addirittura mandarmi una bella mail ;).
In bocca al lupo per il recupero
Ciao Emanuele, mi aggiungo ai complimenti che ti hanno fatto gli altri per l'ottimo articolo! Ti seguo già da un po' sia sui fatti di SEO che live (tranquillo non sono uno stalker :+ ho seguito il tuo intervento all'evento di Altavilla a Milano questa estate..)..Pure io mi sono trovato di fronte ad un sito WordPress bucato, che è stato ripulito – o meglio è stato completamente rifatto da zero – ma ha lasciato la serp piena di url spam parametriche (www.nomesito.it/?key=tag/operating-systems)..Il brutto di queste url è che è impossibile mandarle in 404 perchè reindirizzano alla home del sito. Se le "visualizzo come google" tramite search console vengono visualizzate come la home del sito, se invece guardo quello che Google ha in cache vedo la pagina SPAM..Ne ho provate di ogni ma non sono ancora venuto a capo di come risolvere questo problema, e purtroppo leggendo l'articolo e le risposte ai commenti degli altri utenti non sono riuscito a capire se qualcuna di queste tecniche può funzionare anche in questo caso..Avresti qualche suggerimento da darmi? Grazie in anticipo e complimenti ancora!
Ciao Fabio,
innanzitutto scusa per il ritardo nella risposta ( mi era sfuggita la notifica ) e ti posso assicurare che se la cosa non è relativa al supermercato mi fa piacere che tu mi segua :D.
Allora, mi vengono in mente alcune possibilità:
1) Lavorare su come WP gestisce i parametri e fare un redirect ad un 404 vera per pulire "in automatico" il sito;
2) Reindirizzare a mano ogni URL parametrico forzando il 301 ( Il server penso onori l'ultima istruzione di HTACCESS, ma potrei sbagliarmi );
3) Dire a Google tramite Search Console di ignorare i parametri che portano alle pagine spam se non sono utilizzati anche in modo benigno;
Di quante pagine parliamo? Se mi dai qualche dettaglio sono sicuro di poterti dare una mano. Spero intanto di esserti già stato utile
Salve io per cambio di azienda e nome brand vorrei cancellare definitivamente un sito dall'indice di Google magari indicandogli anche il nuovo sito. Come posso fare?
Salve Marco, con un redirect 301
Ciao Emanuele, complimenti veramente per questo post ..era esattamente quello che stavo cercando ed è spiegato anche per i "non" praticissimi di SEO. La mia necessità è proprio quella di eliminare parecchi risultati e pagine "vecchie" dalla ricerca di google.
Mi sono però sorti alcuni dubbi, mentre stavo facendo qualche tentativo seguendo i tuoi consigli..
1. Ho trovato un plugin di WP che mi permette di fare i 301 delle pagine che non esistono piu, in questo modo dandogli una sitemap con i vecchi link il crawl di google dovrebbe riconoscere che sono 301? in poche parole analizza prima i 404 ricevuti e da li posso indicargli il corretto link ..e credo che cosi facendo gli risponda come 301..
2. Creando una pagina Html come suggerivi, orfana(senza link al reale menu del sito), devo inserirla come pagina /Proprietà su Search Console? Cosi facendo verranno analizzati tutti i link in essa contenuti e di conseguenza farei trovare tutti i 404 relativi ?
3. Se volessi inserire nella pagina tutta una serie di link :
es: http://www.sito.it\portfolio\ ……
C'e' qualche sintassi ? oppure devo inserirli uno ad uno tutti che voglio eliminare dalla ricerca di google?
4. Stavo leggendo nei commenti che indicativamente un paio di settimane potrebbero essere sufficienti per "pulire" dalle ricerche tutte le cose date in pasto .. corretto ?
Per il momento ti ringrazio di aver scritto gia il post sopra 🙂 ..se vuoi darmi qualche altra info te ne sarei grato..
Ciao
Andrea
Ciao Andrea, innanzitutto grazie per il feedback e scusa per il ritardo nella risposta.
1. Se il plugin di permette di reindirizzare le pagine che non esistono più a pagine che DAVVERO sostituiscono la vecchia pagina usali pure. Se invece devi fare 400 redirect alla homepage su pagine che non esistono effettivamente più per paura di avere "errori 404" lascia stare. I 301 servono per le pagine che sono state spostate, i 404 per le pagine che non esistono più. Se hai dei link che puntano ad una pagina che non esiste più puoi fare il 301 ma rimane comunque sensato solo se il contenuto al quale punti la redirezione effettivamente serve gli utenti che cercavano la vecchia pagina. Se non esiste piuttosto crea una pagina in noindex di cortesia e manda un link ad un'altra pagina spiegando perché l'utente atterrato dovrebbe andare proprio li.
2. Devi farla scansionare dal menu della proprietà nella quale risiederà questa pagina dal tool scansione > visualizza come Google;
3. Devi inserirli uno ad uno. Puoi creare liste di url simili molto velocemente con un paio di formule di Excel;
4. Dipende da quante sono, se sono relativamente poche, nell'ordine delle centinaia, e Google scansiona spesso il tuo sito ( diciamo giornalmente il doppio delle tue pagine ) i tempi sono indicativamente quelli;
In bocca al lupo!
Ciao Emanuele, ho letto la tua guida e devo dire che sei stato molto chiaro ed esaustivo, davvero ottima. Ho solo un piccolo dubbio: circa un anno fa ho creato un sito che è stato violato e si sono generate delle pagine spam che non ho mai creato e che puntano alla homepage del mio sito.
Il sito in questione tratta di un rifugio montano nel bresciano (https://www.gamsantemiliano.com/), ed è un piccolo sito con poche pagine ma eseguendo la ricerca su google di gam santemiliano e cliccando sulla dicitura "Altri risultati in gamsantemiliano.com »" ecco comparire la marea di link spam che si erano creati. Per esempio tutti quelli che contengono nella url la voce "exam" sono spam.
Come dovrei agire per eliminarli? Alla fine ci sono solo degli url da eliminale non delle pagine, dato che puntano alla homepage, e questo mi lascia perplesso. Grazie
Ciao Marco,
le pagine spam si vedono dal comando "altri risultati" ma al comando site: non risultano visibili, penso sia un rimasuglio di una qualche cache del sistema di Google relativo all'elemento specifico. Detto questo l'homepage ha un canonical autoreferenziale, quindi non rischi che tornino ad essere indicizzati.
L'unico mio dubbio è che vengano ancora scansionati in fase di crawling, io bloccherei tutte le url contenenti la query inserendo nel robots.txt:
User-Agent:*
Disallow:/?exam*
In questo modo non peseranno sul crawling e vedrai che scompariranno anche dall'elemento "altri risultati". In bocca al lupo!
Ciao Emanuele, complimenti davvero per questa guida.
Vorrei se possibile chiederti un consiglio perché non riesco proprio a uscirne fuori e a trovare una soluzione.
Ho una pagina Facebook e da un pò di tempo mi sono resa conto che quando la cerco dai motori di ricerca come ad esempio Google, questa compare in più link ma tutti in versione mobile con m.facebook e quindi la pagina viene aperta sgranata e ingrandita. Inoltre uno di questi link dá "pagina non trovata". Non vorrei che fosse successo da quando ho cambiato nome utente della pagina Facebook. Google ha salvato anche link vecchi dove c'erano meno mi piace alla pagina ma che comunque sono sempre nella versione mobile. Cosa mi converrebbe fare? Grazie.
Sara
Ciao Sara,
forse il cambio della URL ha confuso Google? Non so esattamente come Facebook gestisca queste cose sinceramente. Hai provato anche da altri PC se ti esce la versione mobile? Temo che tutto quello che tu puoi fare sia in ogni caso aspettare che Google comprenda la situazione e risolva. In bocca al lupo.
Ciao Emanuele,
complimenti, articolo molto esaustivo.
Non ho ben capito una cosa, quando elimino un articolo definitivamente, precedentemente indicizzato da google, quando faccio l'analisi con search console, è normale che mi restituisca successivamente un 404?
Non è che google vendono il 404, ritorna successivamente e perde tempo prezioso sulle pagine che sono state eliminate definitivamente?
grazie!
Vincenzo
Ciao Vincenzo, innanzitutto grazie per i complimenti.
Se l'articolo non esiste più e qualsiasi client richiama la URL nel quale risiedeva avrà in risposta, correttamente, una 404 ( se non forzi altre risposte nell'header HTML ). Googlebot ha il brutto vizio di tornare anche per anni su pagine che non esistono più e l'unico modo che hai per inibire questo comportamento, quando sei sicuro che la pagina sia deindicizzata, è bloccarla da robots.txt. Ma se è solo una pagina ti consiglio semplicemente di lasciar correre. Spero di aver chiarito il tuo dubbio!
Ciao Emanuele, articolo molto esaustivo. Io ho recentemente aggiornato un sito cambiando totalmente argomento. Ho eliminato fisicamente tutte le vecchie pagine da WordPress ed ora tutte queste restituiscono un 404 in Search Console. Dal momento che sono due argomenti completamente diversi, ha senso fare un redirect di queste pagine alla nuva homepage del sito oppure è meglio procedere in qualche altro modo per eliminare dfinitivamente questi 404?
Grazie mille
I 404 non sono intrinsecamente "problemi da eliminare", se le pagine non esistono più e non ci sono pagine che hanno lo stesso significato nel nuovo sito non ha senso fare reindirizzamenti perché non si è spostato nulla. Se non esiste più la pagina lascia che esista 404, Google continuerà a scansionarla per molto tempo ma l'unica cosa che puoi fare è di bloccare la risorsa da robots.txt ( dopo esserti assicurato che non sia più indicizzata ) se proprio vuoi essere pignolo.
PS: grazie del feedback
ciao ottimo articolo … io ho provato ad usare quel tuo che hai segnalato con creando la sitemap con le pagine in errore .. ma poi sinceramente non ho capito cosa fare …
hmhmhmh grazie 1000! ottimo lavoro.
Ciao Maximiliano,
mi spiace di averti risposto solo ora :(. Spiegami cosa non hai capito così provo ad aiutarti
Bell'articolo….ma mi manca un pezzo..quando scrivi questo:
Create un bella pagina orfana ( che non riceve link da nessuna altra pagina del sito ) , possibilmente escludendo gli elementi di navigazione: basterà caricare un bel file html;
Metteteci un meta tag noindex in modo che non venga inserita nell’indice ( è una pagina “tecnica” di nessuna utilità per i vostri utenti );
Come si fa in teoria?
Devo creare una pagina vuota e poi aggiungo un file html a inizio pagina e sotto tutti i link da rimuovere?
Oppure devi inserire tutti i link all'interno della pagina .html e poi caricare il tutto in una pagina vuota su wordpress?
Il tag no-index lo devo inserire nella pagina .html che ho caricato?
Io ho fatto cosi e poi ho inviato la pagina a google "visualizza come google".. ma nelle ricerche di google poi mi porta la mia pagina…quindi è come se non avesse preso il no-index..
Ma se mi dici che il procedimento è quello giusto va bene cosi..Fammi sapere
Ciao Rosario,
perdona il ritardo nella risposta. Venendo al sodo:
– Crei un file HTML con solamente i link verso le pagine da rimuovere e lo carichi direttamente sul server: in questo modo non avrà link di navigazione o altri elementi di struttura presi dal template di WordPress;
– Si, questo file HTML deve avere la direttiva noindex;
– Se hai inserito il noindex in fase di creazione è molto, molto strano che lo indicizzi, hai probabilmente sbagliato qualcosa nella sintassi della direttiva;
Spero di esserti stato utile!
Ciao Emanuele, complimenti per il tuo lavoro!
Ti riassumo la mia situazione:
Sito A, bucato a maggio (iniezione di codice nell'header di WP), nessuna pagina spam. È iniziato un crollo verticale che oggi ancora non si ferma (per intenderci da 6k+ kw posizionate a circa 1k attuali…).
Dopo vari tentativi mi sono convinto a passare ad altro dato che questo sito non riesce più a monetizzare.
Ho creato un SITO B, abbastanza giovane ancora ma con argomenti simili al SITO A.
Qui viene il dubbio… vorrei recuperare alcuni post per me importanti (circa 30 post da 2k parole che erano ben posizionati) dal SITO A per portarli sul SITO B.
La strategia a cui avevo pensato:
1. Sposto i post sul nuovo SITO B
2. Redirect 301 sul vecchio SITO A verso il SITO B
3. Amen
Questo potrebbe in qualche modo influenzare negativamente il SITO B?
Il SITO A andrà a morire lentamente, vorrei recuperare i post e "abbandonarlo".
Come procederesti?
Ciao Chris,
io sinceramente recupererei il sito A. Per diversi motivi non è detto che il sito B abbia le stesse performance. Se invece pulisci il sito e migliori la sicurezza potresti tornare allo stesso livello.
Se però vuoi passare a B devi ripulire A in modo che Google torni a scansionarlo con frequenza e quindi copiare gli articoli e mettere dei redirect 301 come dici tu. Forse ancora meglio, visto che con ogni probabilità Google scansiona molto meno il sito e potrebbe "perdere" i cambiamenti o addirittura passare un segnale negativo visto il sito infetto, io metterei dei canonical dal sito A al sito B controllando che vi sia un passaggio rispetto alle pagine indicizzate.
Ciao,
grazie per il supporto!
Per quanto riguarda il SITO A ho già impiegato diverso tempo per eliminare completamente il malware (eliminato il giorno stesso in cui è stato bucato il sito) e per tentare, senza alcun risultato, di far tornare su il sito (che conserva ancora circa 200kw nella top 10 di Google).
Il dubbio che mi è sempre rimasto nel tempo è relativo ad alcuni guest post che ospito nel sito (circa 30/40 su 100/110 post totali) con argomenti talvolta borderline con gli argomenti trattati.
avere il 30/40% del sito composto da guestpost borderline non è molto salutare per la SEO. Per borderline cosa intendi per altro? Gioco d'azzardo? O ti riferisci ad una ottimizzazione aggressiva?
Ciao Volevo chiederti un chiarimento, siamo un sito ecommerce che opera dal 2007 attualmente sul nuovo search console vediamo che:
– le pagine valide sono 3.699 (in verde)
-le pagine escluse sono 41.010 (in grigio)
di cui 31.378 con reindirizzamento
8703 pagine con alternativa tag canonical appropriato (google aveva preso l'url con le varianti taglia creato dal
nostro cms accorgendosi dopo del canonical)
698 con anomalia durante la scansione
144 scansionata ma non indicizzata
62 bloccate da robots
14 tag noindex
e una decina di altre pagine con errori diversi.
In passato circa due anni fa a causa di professionisti non rivelatisi poi tali abbiamo fatto un po' di casino con gli url generandone tantissimi per le stesse pagine. Ora da un anno e mezzo le cose sono più monitorate e con il nuovo cms abbiamo evitato questi problemi.
Le pagine escluse (41.000) sono da cancellare seguendo i tuoi metodi? per evitare di disperdere authority o crawling budget? Oppure possono restare così tanto non danno fastidio e devo cercare di ottimizzare le 3699 pagine valide?
Altro piccolo suggerimento, avendo parecchi prodotti che stagionalmente non torneranno più disponibili, come giudichi il redirect 301 della pagina prodotto ad un altro prodotto simile o alla pagine di categoria? Ritieni sia meglio il 404?
Ciao Matteo,
se i redirect sono dai duplicati alle pagine "originali" tienili finché non smetterà di proporle in SERP. Fatto ciò accertati che non ci siano riferimenti ai duplicati, come ad esempio da link interni o da sitemap, da togliere, o backlink per i quali lasciare i redirect. Nel caso questi controlli diano esito negativo limitati a togliere i redirect e a fare rispondere le URL 404. Monitora poi l'attività del crawler per assicurarti che non ci siano visite troppo insistenti in quelle pagine: in quel caso cerca di capire perché. Purtroppo è una situazione complessa da trattare in un commento, me ne rendo conto.
Riguardo il trattamento delle pagine di prodotti non più in vendita ti rimando ad un mio podcast: https://www.spreaker.com/user/10485906/seo-prodotti-ecommerce-che-non-vendi-piu
Ciao Emanuele,
ti ringrazio tantissimo per questo articolo dettagliato, aggiornato e molto comprensibile. Volevo una conferma. Io ho la necessità di togliere dall'indice un intero ambiente di staging Mi pare di aver capito che il meta-tag e la direttiva X-Robots lavorino allo stesso modo per cui al posto di andare a modificare l'HTML di ogni pagina all'interno del sito lavorerei su apache inserendo qualcosa del genere
<Location ~ "/areaDemo">
Header set X-Robots-Tag "noindex, nofollow"
</Location>
Mi confermi che in questo modo ottengo lo stesso effetto del meta tag noindex? Anzi in questo modo blocco la serp sia su pagine HTML che sui file pdf, immagine ecc.
Grazie mile 🙂
Perdonami, non devo rimuovere dall'indice (perché come hai spiegato ormai ci sta dentro) ma mi basta che sia rimossa dal SERP.
Ammesso e non concesso che la strada del X-robot che hai delineato è corretta per far sparire dalle SERP l'area di staging, se la vuoi far sia rimuovere dalle SERP che deindicizzare puoi anche semplicemente chiudere la cartella dietro password htaccess: dopo aver visto che per X giorni/settimane il contenuto è privato e inaccessibile Google cancellerà tutto anche dall'indice ( e nel mentre gli utenti non potranno comunque accedervi ). Solitamente io le app di staging le "varo" già protette da password così non ci entra neanche da link strani tipo la mail girata al cliente ( ci sono test piuttosto inquietanti a riguardo… 🙂 ).
PS: scusa il ritardo nella risposta!
Ti confermo che per far de-indicizzare i contenuti della cartella il codice è quello giusto.
Ciao Emanuele, complimenti per il sito!
Stamattina mentre indicizzavo un pagina del mio sito (un hobby), ho visto che la 4° query era questa "cardioaspirina e disfunzione erettile" e purtroppo ho scoperto che ho una pagina collegata al mio sito con la vendita di Viagra.! Come posso cancellare questa pagina (che io non ho fatto) e toglierla definitivamente da Google?
Grazie!
Ciao Bianca, grazie per il feedback gentile.
Se hai delle pagine relative al Viagra sul tuo sito vuol dire che è stato "bucato", ovvero qualcuno si è introdotto dentro al sito inserendo del codice. Quello che dovresti fare è "pulire" il sito, un processo lungo da spiegare per il quale esistono tantissime guide sul web, alle quali ti rimando. E' una bella scocciatura ma si può risolvere. Ti consiglio anche di seguire una guida relativa al miglioramento della sicurezza del tuo sito dopo che avrai risolto il problema. Buon lavoro!
Emanuele, grazie davvero per il tuo supporto e per questo articolo!
Sono alle primissime armi.
Mi trovo a metter mano su un e-commerce che, a fronte di 400 prodotti, si ritrova con oltre 2000 vecchie url regolarmente scansionate e indicizzate dal crawler (sezioni e prodotti cancellati nel tempo, che non ci interessa riproporre, più url strane generate dalla migrazione da un cms all'altro…). Ora, la voglia è quella di cancellare fisicamente queste pagine dal cms (e quindi generare tanti 404 che nessuno mai vedrà. Non ci sono redirect né link esterni). Però mi pare di capire che il crawler di Google continui a visitare il 404 per molto tempo, anche anni (perdendo tempo e crawling budget). Pensavo di dare un no index, aspettare un po' (un paio di mesi?) e poi eliminarle. E se il bot continua ad andare sul 404, dare a quel punto un disallow su robots.txt. Che dici, può andare?
Grazie mille!
Ciao Simona,
Google le pagine le continuerà a visitare per anni che esse siano noindex, 404, 410 o altro, è una sua prerogativa incaponirsi e perdere tempo :). Cancellale pure senza problemi. Il disallow su robots.txt in questi casi non lo consiglio perché preferisco rendermi conto se è ossessionato da una certa pagina e cercare di capirne perché. Magari ne puoi fare una nuova alla stessa URL!
Ciao,
stiamo seguendo le tue linee guida ma abbiamo una domanda.
Da pochi giorni la vecchia versione della Search Console di Google non è più disponibile e quindi non c'è più la sezione "Visualizza come Google" che ora corrisponde a "Controllo url" ma non prevede l'opzione “invia all’indice” dicendogli di scansionare tutti i link diretti presenti nella pagina. come possiamo procedere? noi abbiamo creato la pagina orfana contenente gli url da deindicizzare ma non riusciamo a passarla alla search console come descritto nella sezione "Il metodo della pagina con i link verso le 404".
grazie e buona giornata,
Lorena
Ciao Lorena,
grazie per il commento: effettivamente devo aggiornare la guida. C'è l'opzione "richiesta di indicizzazione" che penso possa fare la stessa cosa. Grazie ancora per avermelo fatto notare.
Ciao Emanuele ieri ho cancellato delle foto dal sito che le ha pubblicate senza la mia autorizzazione e ho anche fatto fare la rimozione da Google ma stamattina nella ricerca da Google le vedo ancora sai aiutarmi per favore ?
Grazie mille
Salve Dalila,
spero che a quasi un mese di distanza (rispondo con molto ritardo) il problema sia ora risolto: nel tuo caso dovrebbe essere stata solo una "questione di tempo". Se le foto non sono più presenti nel sito Google le "dimenticherà" nel giro di qualche giorno/settimana, dipendentemente da quanto è popolare il sito e la chiave di ricerca con la quale si trovano le fotografie: meno è popolare più tempo ci metterà a "rendersene conto". Spero di averti chiarito le idee!
Ciao Emanuele,
Ho creato la pagina .html come hai indicato. Nel momento in cui la do in pasto a GSC (nuova versione) nello strumento "Controllo URL", compare il messaggio:
"Richiesta di indicizzazione rifiutata.
Durante il test in tempo reale sono stati rilevati problemi di indicizzazione relativi all'URL."
Il problema in questione è dovuto al tag no index che blocca il prosieguo dell'operazione…
Ammesso che abbiamo svolto tutto correttamente.. come posso risolvere ???
Grazie e complimenti per l'articolo
Ciao Fernando,
anche se la pagina non viene indicizzata non è un problema: quello che conta è che Google la visiti e che navighi anche le pagine che a loro volta ricevono link dalla pagina stessa. Avete usato anche il metodo della sitemap? A 20 giorni di distanza i contenuti sono stati cancellati?
Caro Emanuele,
innanzi tutto: complimenti.
Volevo chiederti, per favore, aiuto. Molti anni fa, all'inizio degli anni Duemila, un conoscente in pensione ma desideroso di cimentarsi nella costruzione di siti utilizzò materiale da un sito internet che amministro personalmente. Quel vecchio esperimento morì lì, ma ancora oggi, dopo sedici anni (l'ultimo aggiornamento del sito 'parallelo' risale al 2003), Google indicizza tutti e due i siti, il vecchio (che contiene anche imprecisioni, oltre a informazioni decadute) e quello originale e aggiornato. Una bella seccatura. Parlando con l'amico pensionato, ha dichiarato candidamente di non ricordare più nulla: password, account, come gestire, niente. Credo che attualmente abbia difficoltà anche solo a navigare su internet, forse perché ormai viaggia su quote genetliache piuttosto elevate… Si può sperare di risolvere il maldestro duplicato?
Grazie! E buona continuazione del tuo ottimo e gradito servizio alla comunità.
Antonella
Buonasera Antonella,
se il sito contiene materiale di tua proprietà puoi chiederne la rimozione direttamente all'hosting, così come se il proprietario del dominio in questione è il signore pensionato può fare richiesta al registrante del dominio per la ri-acquisizione dello stesso. Nome utente e password si possono altresì facilmente recuperare presso l'hosting utilizzato.
Spero di esserti stato utile!
Ciao Emanuele complementi per la guida molto dettagliata.
Ho un problema che riguarda appunto la rimozione di molti url da un sito, il quale è stato bucato e il codice malevolo ha generato centinaia e centinaia di pagine ma che in realtà non esistono, nel backend di wp infatti non sono presenti, andando in search cosole ho trovato quasi 900 errori 404, li ho prontamente segnalati come "risolti" e nel giro di qualche giorno tutti questi errori sono spariti.
Ho ripulito completamente il sito e ripristinato tutti i contenuti, ma ora, sempre tramite search console mi risultano "Indicizzate, ma non inviatate tramite la Sitemap" altri 600 url, ovviamente anche questi url non esistono realmente, quindi cosa mi consigli di fare, aspetto che google me li classifichi come 404 e poi dichiaro di averli corretti? o di bloccare questi url finti in un'altra maniera?
Grazie in anticipo.
Ciao Gigi, innanzitutto scusa per la risposta arrivata molto in ritardo.
Dichiarare gli errori come corretti su Search Console non fa cambiare idea a Google. Quello che devi fare, una volta appurato che le pagine rispondano con un "hard 404", ovvero che passano effettivamente come header HTTP lo stato di 404, è mostrarle il più possibile a Google con la strategia della sitemap inversa e in generale tutte quelle che ho segnalato in questa guida. In questo modo, nel tempo, digerirà lo status di 404 di questi link. Detto questo spero che nel frattempo Google abbia già fatto passi avanti in questo senso :).
Ciao Emanuele, ho necessita di eliminare un Url di un website test creato con Google Sites Classic version. La pagina non esiste più ma purtroppo è ancora indicizzata da Google. In casi simili, non potendo fare molto, come posso chiedere a Google di rimuovere quell' Url ? Mille grazie !
Se la pagina non esiste più e risponde 404 non devi fare altro che aspettare. Se hai molta fretta perché ad esempio la pagina contiene dati sensibili segnalalo all'assistenza, non ho esperienze dirette in questo senso ma tentare non ti costa nulla.
Ciao e complimenti per l'articolo.
Ho un problema con quattro siti differenti che per errore sono stati indicizzati da Google.
Questi quattro siti erano di sviluppo e le url indicizzate riportano il dominio aziendale e il sottodominio ( che ora è diventato il dominio principale ).
Ora al momento della pubblicazione online sono stati eliminati i siti di sviluppo, ma l'indicizzazione è rimasta, buttando via tutto il lavoro di web reputation fatto.
Come posso dire a Google di non indicizzare queste pagine in modo rapido, nonostante non abbia più a disposizione i quattro siti di sviluppo?
Grazie.
Ciao Daniele,
immaginando che tu possa avere accesso alle installazioni di questi siti dovresti fare dei redirect 301 delle pagine in staging verso quelle in produzione. Le altre le puoi lasciare andare in 404 e seguire i consigli di questa guida per velocizzare la de-indicizzazione.
Ciao Emanuele, mi trovo a che fare proprio con un sito che ha numerosissime pagine molto datate (dal 2012) in cui sono presenti eventi vecchi, poco testo o solo immagini. In più presenta più di 6000 categorie, di cui effettivamente utilizzate per lo scopo per cui si crea una categoria, meno di 30.
Ora, ho letto che hai tagliato migliaia di pagine in un colpo solo. Io sto procedendo pian pianino con la rimozione delle categorie, tipo 10/20 alla settimana, ma mi rendo conto che così non finisco più. Credi che possa calcare di più la mano nella stessa tua maniera, senza avere grosse ripercussioni? Il sito mi è stato affidato perchè il traffico è diminuito vertiginosamente. Credendo che sia un problema di thin content, ho iniziato a tagliare.
Grazie
Ciao Paolo,
se pensi che il problema sia il thin content (ed effettivamente se ci sono 6000 categorie di cui solo 30 valide il dubbio mi sembra legittimo) taglia tutto insieme. Se il sito contiene effettivamente tante pagine inutili tagliarle non può che fare bene. Ricordati di gestire bene il crawling delle pagine cancellate, segui la guida! Buona lavoro.
Grazie Emanuele. Il tuo parere mi conforta. E allora adesso… Banzaiiiiii!!!!!
Prego! Fammi poi sapere com'è andata!
Sicuramente. Per ora sto tagliando le prime 1000 categorie. Ovvero, sto creando la sitemap dei 404 da inviare a google appena le cancello effettivamente.
Ciao! ho eliminato un sito dal server lasciando solo una landing page a titolo informativo; per accellerare la rimozione di tutti gli url dai risultati di google cosa mi consiglieresti? io ho provveduto a creare una nuova sitemap con la sola pagina index. E' l'unico modo oppure esiste un modo più veloce? (il sito aveva piu di 3000 links).
Grazie se mi risponderai 🙂
Buonasera Leo, mi spiace risponderti così in ritardo. Segui i vari metodi in questa guida per segnalare le pagine: sitemap inversa, sitemap HTML sul quale fare andare il crawler etc. etc.
Ciao, su un mio sito in joomla ho il meta <meta name="robots" content="noindex, nofollow" /> da molti mesi ma il sito è sempre indicizzato…perché? Come lo tolgo dai motori di ricerca?
Ciao Fabio, mi spiace risponderti solo ora. Innanzitutto togli il "nofollow": non permette a Google di navigare il sito se non dalla pagina nella quale atterra. Se il crawler non può "accorgersi" che le pagine sono in noindex navigando il sito ci metterà mesi se non anni a deindicizzarlo tutto.
Buongiorno Sig. Emanuele, mi chiamo Andrea, ho letto il suo articolo con molto piacere. Complimenti!
Tuttavia rimane una questione non trattata nei casi da lei indicati, ossia: come rimuovere un url o de-indicizzare un articolo pubblicato da una testata giornalistica quando il web master non vuole? Anche google se nin sei proprietario, non rimuove alcun url alla semplice richiesta.
Come fare?
Cordiali saluti
Salve Andrea, mi spiace risponderle solo ora. In realtà, come specificato all'inizio dell'articolo, la guida riguarda espressamente siti dei quali si è proprietari e per i quali si ha accesso ai file. Le pagine dei siti altrui le possono rimuovere solo i webmaster. L'unico modo lecito per "forzare" la rimozione è passare alle vie legali e avere le autorità che ordinano al webmaster di togliere tali contenuti.
Buongiorno Emanuele,
innanzitutto complimenti per la tua chiarezza. competenza e completezza.
Dovrei gestire un sito .com che è stato hackerato circa 4 mesi fa e su Google, al comando site: nomesito.com rispondono centinaia di migliaia di pagine che puntano al sito .com.
Come faccio a rimuovere questo mare di indicizzazione inesistente? (il sito è disabilitato, fuori linea da mesi)
Avrei poi deciso di rifare il sito su punto .it posso fare un redirect 301 senza che tutti i link-spam poi puntino al sito .it? O che tipo di redirect conviene fare dal .com?
Grazie infinite
Augusto
Buonasera Augusto,
rispondo solo ora perché non avevo visto la notifica della mail. Innanzitutto grazie per le belle parole.
Le URL delle pagine hackerate lasciale semplicemente in 404: Google se ne dimenticherà nel tempo. Dico "nel tempo" perché purtroppo l'ho visto tenersele strette per anni. Ci sono modi per velocizzare il processo ma fanno più danno che utile: quello che ti consiglio è davvero, semplicemente, di lasciare le pagine in 404.
Riguardo al nuovo sito .it non fare il redirect dell'intero dominio ma mappa le pagine veramente esistenti (ad esempio con un crawler) in modo da non fare il redirect anche delle hackerate: se lo facessi Googlebot, visto che comunque proverà tantissime volte a "tornare a vedere" se esistono, finirebbe nel nuovo sito "dalla porta sbagliata". Invece mappa le URL e fai un redirect 1 a 1 se non sono troppe pagine. Spero di averti aiutato!